关于文件系统的lab
File system preliminaries
我们要完成一个相对简单的文件系统,其可以实现创建、读、写以及删除在分层目录结构中组织的文件。目前我们的OS只支持单用户,因此我们的文件系统也不支持UNIX文件拥有或权限的概念。同时也不支持硬链接、符号链接、时间戳或是特别的设备文件。
On-Disk File System Structure
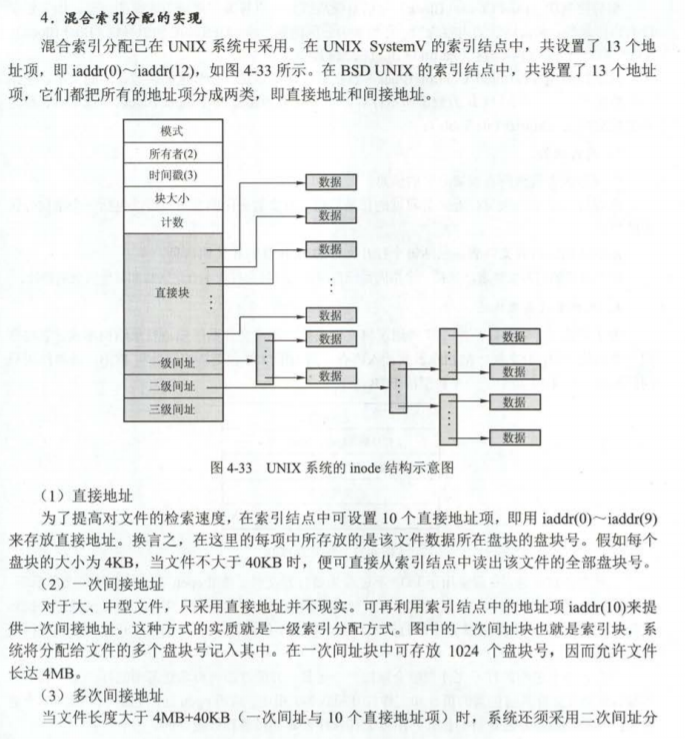
大多是 Unix 文件系统将磁盘空间分为 inode和数据 区域。目录包含文件名和指向inode的指针; 如果文件系统中的多个目录引用该文件的inode,则称文件是硬链接的。由于我们的文件系统不需要支持硬链接,因此我们不需要这一间接层并且能做一个方便的简化:我们的文件系统根本不使用inode,相反我们仅仅将所有文件(或子目录)的 meta-data存储在描述该文件的唯一的目录中(directory entry)。 文件和目录逻辑上都是由一系列数据blocks组成,这些blocks分散在磁盘中,文件系统屏蔽blocks分布的细节,提供一个可以顺序读写文件的接口。
补充 inode
操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据都储存在“块”中,那么很显然,我们还必须找到一个地方储存文件的“元信息”,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做*inode*,中文译名为”*索引节点*“。 具体包括以下内容
1 | * 文件的字节数 |
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
Sectors and Blocks
大部分磁盘都是以Sector为粒度进行读写,JOS中Sectors为512字节。文件系统以block为单位分配和使用磁盘。注意区别,sector size是磁盘的属性,block size是操作系统使用磁盘的粒度。JOS的文件系统的block size被定为4096字节 ( 4kB ) 。
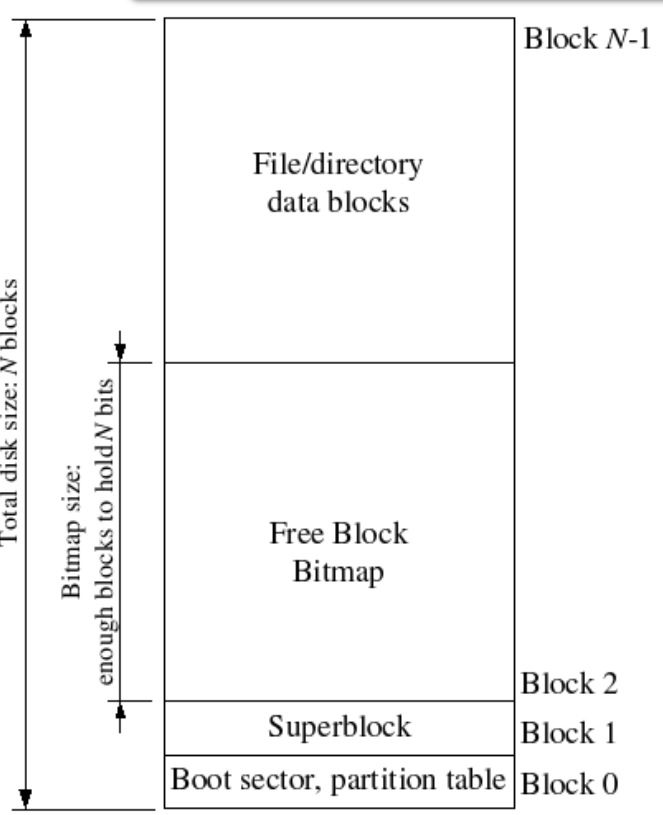
Superblocks
我们的文件系统使用一个superblock,位于磁盘的block 1。block 0被用来保存boot loader和分区表。
我们的文件系统使用一个superblock,位于磁盘的block 1。block 0被用来保存boot loader和分区表。
1 | struct Super { |
File Meta-data
我们的文件系统使用struct File结构描述文件,该结构包含文件名,大小,类型,保存文件内容的block号。struct File结构的f_direct数组保存前NDIRECT(10)个block号,这样对于10*4096=40KB的文件不需要额外的空间来记录内容block号。对于更大的文件我们分配一个额外的block来保存4096/4=1024 block号。
1 | inc/fs.h |
Directories versus Regular Files
File结构既能代表文件也能代表目录,由type字段区分,文件系统以相同的方式管理文件和目录,只是目录文件的内容是一系列File结构,这些File结构描述了在该目录下的文件或者子目录。超级块中包含一个File结构,代表文件系统的根目录。
The Block Cache
我们的文件系统最大支持3GB,文件系统进程保留从0x10000000 (DISKMAP)到0xD0000000 (DISKMAP+DISKMAX)固定3GB的内存空间作为磁盘的缓存。比如block 0被映射到虚拟地址0x10000000,block 1被映射到虚拟地址0x10001000以此类推。
由于我们的文件系统有独立于系统中其他环境的虚拟地址空间(不重叠),因为我们的文件系统唯一需要做的事是实现文件的 access。如此看来我们为文件系统保留大量的空间也是十分合理的。
如果将整个磁盘全部读到内存将非常耗时,所以我们将实现按需加载,只有当访问某个block对应的内存地址时出现页错误,才将该block从磁盘加载到对应的内存区域,然后重新执行内存访问指令。
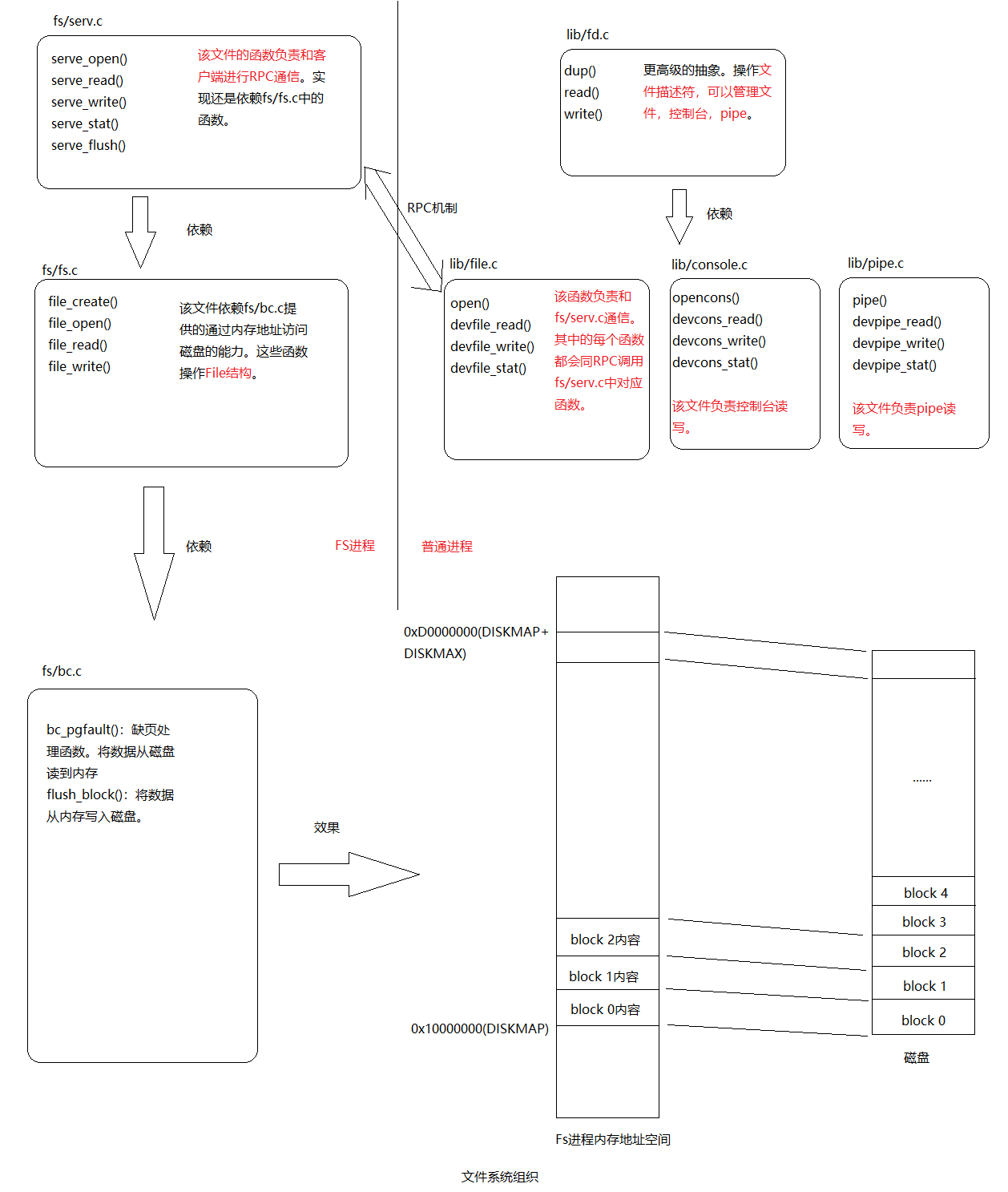
The file system interface
到目前为止,文件系统进程已经能提供各种操作文件的功能了,但是其他用户进程不能直接调用这些函数。我们通过进程间函数调用(RPC)对其它进程提供文件系统服务。RPC机制原理如下:
RPC(Remote Procedure Call )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
本质上RPC还是借助IPC机制实现的。
在开始时,read只需调度到适当的设备读取函数,就可以适用于任何文件描述符,在本例中为devfile_read(我们可以有更多的设备类型,如管道)。 devfile_read专门为磁盘文件实现读取。 这个和lib / file.c中的其他devfile_ *函数实现了FS操作的客户端,并且所有工作都以大致相同的方式工作,在请求结构体中捆绑参数,调用fsipc发送IPC请求,以及解包和返回 结果。 fsipc函数只处理向服务器发送请求和接收回复的常见细节。
相关数据结构之间的关系可用下图来表示:

Sharing library state across fork and spawn
通过给页表项设置PTE_SHARE标志,然后在拷贝页表时直接让他们对相同的物理地址进行映射,达到共享内存的效果。
总结回顾
通过给页表项设置PTE_SHARE标志,然后在拷贝页表时直接让他们对相同的物理地址进行映射,达到共享内存的效果。
引入一个
文件系统进程的特殊进程,该进程提供文件操作的接口。具体实现在fs/bc.c,fs/fs.c,fs/serv.c中。建立RPC机制,客户端进程向FS进程发送请求,FS进程真正执行文件操作。客户端进程的实现在lib/file.c,lib/fd.c中。客户端进程和FS进程交互可总结为下图
支持从磁盘加载程序并运行。实现spawn(),该函数创建一个新的进程,并从磁盘加载程序运行,类似UNIX中的fork()后执行exec()。